
Research Grant Positions Available! · 07/12/2024
👉 We have open research grant positions within the PRIN projects "MUCES - a Multimedia platform for Content Enrichment and Search in audiovisual archives" and "MUSMA: Multimedia Understanding meets Social Media Analysis". If you are interested, please get in touch!
News
Paper accepted to NeurIPS 2024 · 09/26/2024
Our paper, "Personalized Instance-based Navigation Toward User-Specific Objects in Realistic Environments", has been accepted to NeurIPS 2024, Datasets and Benchmarks track!

Introducing LLaVa-MORE · 08/03/2024
🔥 Today we are introducing LLaVA-MORE, a family of models that enhances LLaVA by integrating LLaMA 3.1 as the language model. Check out our Github repo!

Oral paper accepted to BMVC 2024 · 07/20/2024
Our paper, "Revisiting Image Captioning Training Paradigm via Direct CLIP-based Optimization", has been accepted for oral presentation to BMVC 2024!

MINERVA proposal successful! · 07/04/2024
Our proposal MINERVA, submitted to the DIGITAL-EUROHPC-JU-2023-AISC-03-01 call, and coordinated by CINECA, has been successfully approved!
Three papers accepted at ECCV 2024! · 07/01/2024
Glad to announce that we have three papers accepted at ECCV 2024: "Safe-CLIP: Removing NSFW Concepts from Vision-and-Language Models", "Contrasting Deepfakes Diffusion via Contrastive Learning and Global-Local Similarities" and "BRIDGE: Bridging Gaps in Image Captioning Evaluation with Stronger Visual Cues".
Paper accepted to ACL 2024 · 05/16/2024
Our paper, "The Revolution of Multimodal Large Language Models: A Survey", has been accepted to the ACL 2024 Findings!

ELLIS Scholar · 07/29/2021
I have been elected as an ELLIS Scholar in the ELLIS society, the European Laboratory for Learning and Intelligent Systems.

Interview with La Repubblica · 09/23/2020
I have been interviewed by Jaime D'Alessandro on Rep: Scienze, about Gpt-3 and Transformed-based language models. You can read the article here.

LAMV is being used at Facebook to detect harmful content · 08/05/2019
Our solution for matching and detecting copied videos, published in CVPR 2018, is now being used in production scale at Facebook to detect harmful content.
See the official announcement on the Facebook newsroom website, and the Github repository with the source code.
Older news can be found in the news archive.
Featured publications
Complete list is available in the publications page.

Personalized Instance-based Navigation Toward User-Specific Objects in Realistic Environments
Luca Barsellotti, Roberto Bigazzi, Marcella Cornia, Lorenzo Baraldi, Rita Cucchiara
NeurIPS 2024

What’s Outside the Intersection? Fine-grained Error Analysis for Semantic Segmentation Beyond IoU
Maximilian Bernhard, Yannic Kindermann, Roberto Amoroso, Matthias Schubert, Lorenzo Baraldi, Rita Cucchiara, Volker Tresp
Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision (WACV)






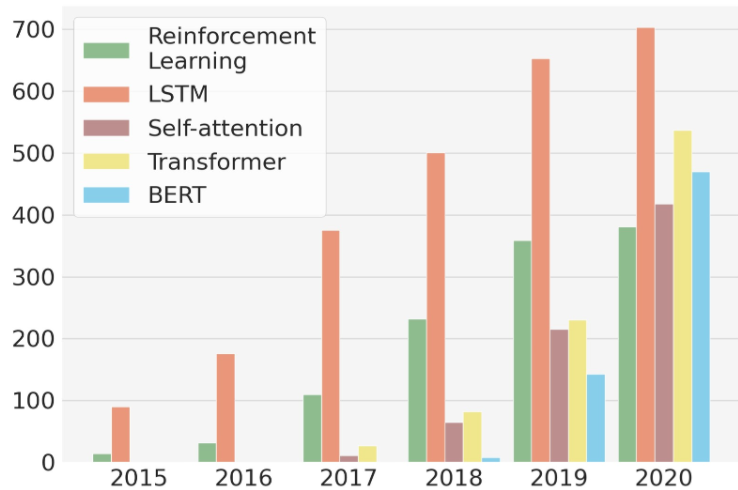
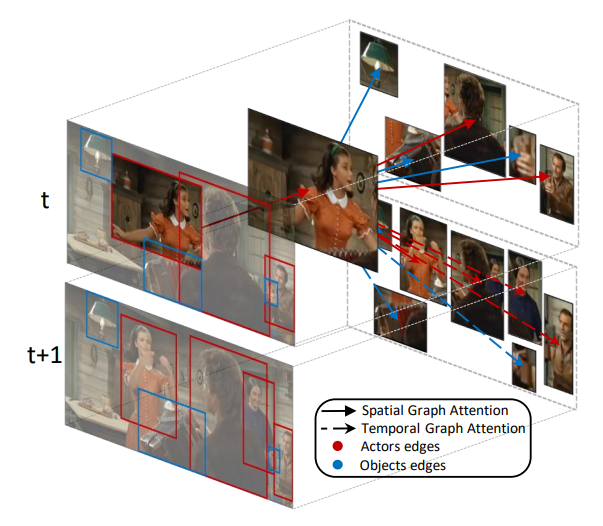

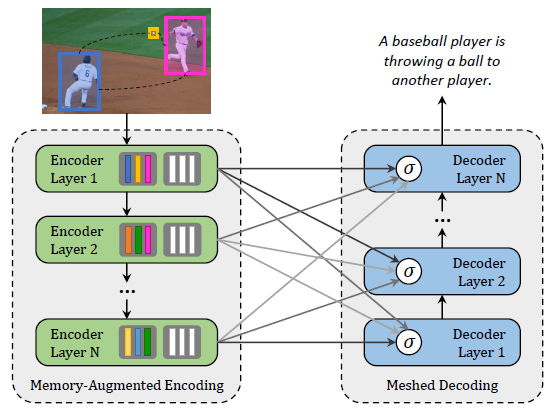




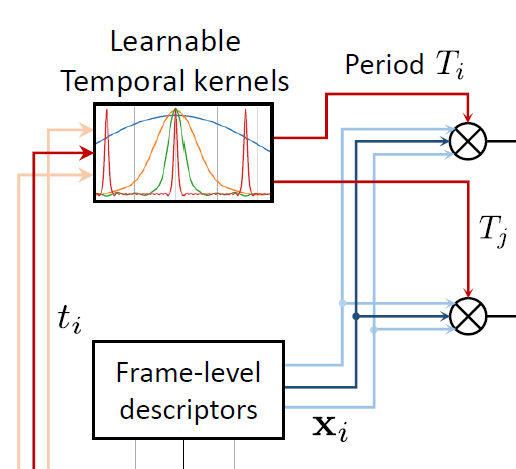
Teaching
Complete list is available in the teaching page.
Architettura dei Calcolatori (2024/2025)
Course material
Ingegneria Informatica
Rita Cucchiara, Lorenzo Baraldi
Computer Vision and Cognitive Systems (2023/2024)
Course material
· Upcoming exams
Laurea Magistrale in Ingegneria Informatica
Lorenzo Baraldi, Vittorio Cuculo
AI for Automotive (2023/2024)
Electronic Engineering for Intelligent Vehicles
Rita Cucchiara, Lorenzo Baraldi
Scalable AI (2023/2024)
Course material
Laurea Magistrale in Ingegneria Informatica
Lorenzo Baraldi, Giuseppe Fiameni, Marta Lovino